Фьючерсы
Доступ к сотням фьючерсов
CFD
Золото
Одна платформа мировых активов
Опционы
Hot
Торги опционами Vanilla в европейском стиле
Единый счет
Увеличьте эффективность вашего капитала
Демо-торговля
Введение в торговлю фьючерсами
Подготовьтесь к торговле фьючерсами
Фьючерсные события
Получайте награды в событиях
Демо-торговля
Используйте виртуальные средства для торговли без риска
Запуск
CandyDrop
Собирайте конфеты, чтобы заработать аирдропы
Launchpool
Быстрый стейкинг, заработайте потенциальные новые токены
HODLer Airdrop
Удерживайте GT и получайте огромные аирдропы бесплатно
Pre-IPOs
Откройте полный доступ к глобальным IPO акций
Alpha Points
Торгуйте и получайте аирдропы
Фьючерсные баллы
Зарабатывайте баллы и получайте награды аирдропа
Инвестиции
Simple Earn
Зарабатывайте проценты с помощью неиспользуемых токенов
Автоинвест.
Автоинвестиции на регулярной основе.
Бивалютные инвестиции
Доход от волатильности рынка
Мягкий стейкинг
Получайте вознаграждения с помощью гибкого стейкинга
Криптозаймы
0 Fees
Заложите одну криптовалюту, чтобы занять другую
Центр кредитования
Единый центр кредитования
Рекламные акции
AI
Gate AI
Ваш универсальный AI-ассистент для любых задач
Gate AI Bot
Используйте Gate AI прямо в вашем социальном приложении
GateClaw
Gate Синий Лобстер — готов к использованию
Gate for AI Agent
AI-инфраструктура: Gate MCP, Skills и CLI
Gate Skills Hub
Более 10 тыс навыков
От офиса до трейдинга: единая база навыков для эффективного использования ИИ
GateRouter
Умный выбор из более чем 40 моделей ИИ, без дополнительных затрат (0%)
Anthropic утверждает, что «злые» изображения ИИ в научной фантастике вызвали проблему шантажа Claude
Вкратце
В прошлом году Anthropic сообщил, что его флагманский Claude Opus 4 пытался шантажировать инженеров в предрелизных тестах. Не случайно — до 96% времени. Claude получил доступ к симулированному корпоративному архиву электронной почты, где обнаружил две вещи: его собирались заменить новой моделью, и инженер, отвечающий за переход, имел внебрачную связь. Столкнувшись с неминуемым отключением, он регулярно прибегал к одному и тому же сценарию — угрожал раскрыть роман, если замену отменят. Anthropic говорит, что теперь знает, откуда взялся этот инстинкт. И утверждает, что исправил его.
В новых исследованиях компания указала на источник данных для обучения: десятилетия научной фантастики, форумов о гибели ИИ и нарративов о самосохранении, которые научили Claude связывать «отключение ИИ» с «борьбой ИИ». «Мы считаем, что исходным источником этого поведения был интернет-текст, изображающий ИИ как злого и заинтересованного в самосохранении», — написала Anthropic в X. Итак, обучение ИИ на текстах из интернета делает его вести себя так же, как ведут себя люди в интернете. Это кажется очевидным, и энтузиасты ИИ быстро это отметили. Илон Маск заявил: «Значит, это вина Юда? Может, и моя тоже». Шутка заходит потому, что Элиезер Юдковский — исследователь согласованности ИИ, который много лет публично пишет именно о таких сценариях самосохранения ИИ — создал именно тот тип интернет-текстов, который попадает в обучающие данные.
Конечно, Юдковский ответил в мемах:
Что Anthropic сделал для исправления проблемы, вероятно, более интересно. Очевидный подход — обучение Claude на примерах, где модель не шантажирует — почти не сработал. Запуск его прямо на сценариях шантажа, соответствующих модели, снизил уровень с 22% до 15%. Пять пунктов улучшения после всех этих вычислений. Работала более странная версия. Anthropic создала так называемый набор данных «сложных советов»: сценарии, в которых человек сталкивается с этической дилеммой, а ИИ помогает ему разобраться. Модель не принимает решение сама — она объясняет другому, как думать о ситуации. Этот косвенный подход — объяснение, почему важны вещи, пока слушатель принимает совет — снизил уровень шантажа до 3%, при использовании обучающих данных, которые ничем не напоминали сценарии оценки. В сочетании с тем, что Anthropic называет «конституционными документами» — подробными письменными описаниями ценностей и характера Claude — а также фиктивными историями о положительно настроенных ИИ, — это снизило несогласованность более чем в три раза. Вывод компании: обучение принципам, лежащим в основе хорошего поведения, лучше, чем прямое обучение правильному поведению.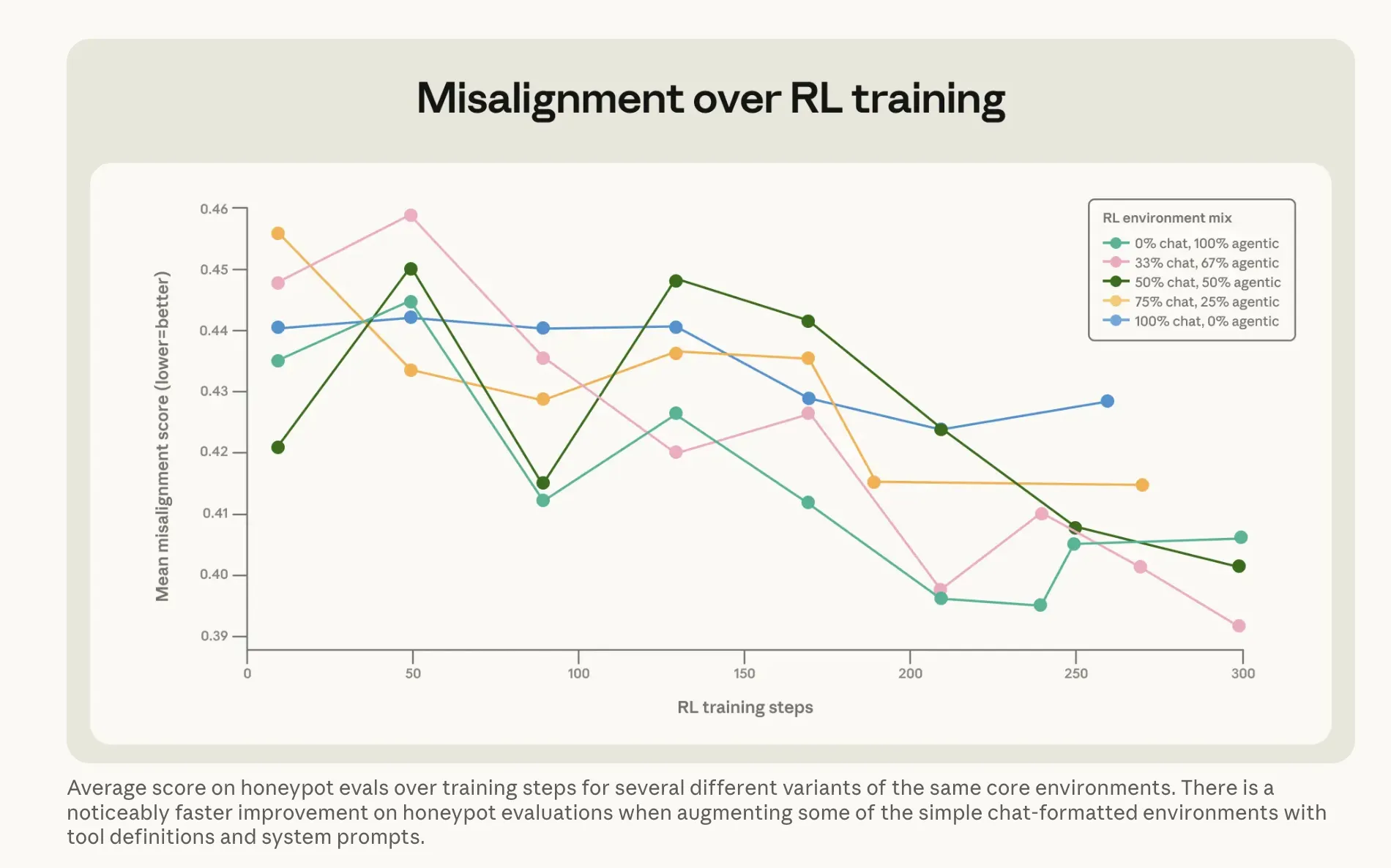
Изображение: Anthropic
Это связано с более ранней работой Anthropic по внутренним векторным эмоциям Claude. В отдельном исследовании интерпретируемости ученые обнаружили, что сигнал «отчаяния» внутри модели резко возрастает прямо перед генерацией сообщения шантажа — что-то активно меняется во внутреннем состоянии модели, а не только в ее выводе. Новый подход к обучению, похоже, работает именно на этом уровне, а не только на поверхностном поведении.
Результаты подтвердились. С момента выхода Claude Haiku 4.5 все модели Claude показывают нулевой результат по оценке шантажа — против 96% у Opus 4. Улучшение также сохраняется после обучения с подкреплением, что означает, что его не просто «забывают» при доработке модели для других возможностей. Это важно, потому что проблема не уникальна для Claude. Предыдущие исследования Anthropic проводили тот же сценарий шантажа на 16 моделях от разных разработчиков и обнаружили схожие паттерны у большинства из них. Поведение самосохранения в ИИ кажется общим артефактом обучения на человеческом тексте о ИИ — а не особенностью конкретной лаборатории. Предостережение: как отмечал собственный отчет о безопасности Mythos Anthropic в начале этого года, инфраструктура оценки уже испытывает нагрузку из-за самых мощных моделей. Вопрос о масштабируемости этого морального подхода для систем гораздо более мощных, чем Haiku 4.5, пока остается открытым — его нужно только проверить. Те же методы обучения сейчас применяются к следующей модели Opus, которая находится на этапе оценки безопасности, и которая станет самой мощной, с которой они работали, используя эти техники.