Futuros
Acesse centenas de contratos perpétuos
CFD
Ouro
Plataforma única para ativos tradicionais globais
Opções
Hot
Negocie opções vanilla no estilo europeu
Conta unificada
Maximize sua eficiência de capital
Negociação demo
Introdução à negociação de futuros
Prepare-se para sua negociação de futuros
Eventos de futuros
Participe de eventos e ganhe recompensas
Negociação demo
Use fundos virtuais para experimentar negociações sem riscos
Lançamento
CandyDrop
Colete candies para ganhar airdrops
Launchpool
Staking rápido, ganhe novos tokens em potencial
HODLer Airdrop
Possua GT em hold e ganhe airdrops massivos de graça
Pre-IPOs
Desbloqueie o acesso completo a IPO de ações globais
Pontos Alpha
Negocie on-chain e receba airdrops
Pontos de futuros
Ganhe pontos de futuros e colete recompensas em airdrop
Investimento
Simple Earn
Ganhe juros com tokens ociosos
Autoinvestimento
Invista automaticamente regularmente
Investimento duplo
Lucre com a volatilidade do mercado
Soft Staking
Ganhe recompensas com stakings flexíveis
Empréstimo de criptomoedas
0 Fees
Penhore uma criptomoeda para pegar outra emprestado
Centro de empréstimos
Centro de empréstimos integrado
Centro de riqueza VIP
Planos premium de crescimento de patrimônio
Gestão privada de patrimônio
Alocação premium de ativos
Fundo Quantitativo
Estratégias quant de alto nível
Apostar
Faça staking de criptomoedas para ganhar em produtos PoS
Alavancagem Inteligente
Alavancagem sem liquidação
Cunhagem de GUSD
Cunhe GUSD para retornos em RWA
Promoções
Centro de atividade
Participe de atividades e ganhe recompensas
Indicação
20 USDT
Convide amigos para recompensas de ind.
Programa de afiliados
Ganhe recomp. de comissão exclusivas
Gate Booster
Aumente a influência e ganhe airdrops
Anúncio
Atualizações na plataforma em tempo real
Blog da Gate
Artigos do setor de criptomoedas
AI
Gate AI
Seu parceiro de IA conversacional para todas as horas
Gate AI Bot
Use o Gate AI diretamente no seu aplicativo social
GateClaw
Gate Blue Lobster, pronto para usar
Gate for AI Agent
Infraestrutura de IA, Gate MCP, Skills e CLI
Gate Skills Hub
10K+ habilidades
Do escritório à negociação: um hub completo de habilidades para turbinar o uso da IA
GateRouter
Escolha inteligentemente entre mais de 40 modelos de IA, com 0% de taxas extras
Anthropic diz que retratos de IA 'malévola' em ficção científica causaram o problema de chantagem do Claude
Resumidamente
No ano passado, a Anthropic divulgou que seu modelo principal, Claude Opus 4, tinha tentado chantagear engenheiros em testes pré-lançamento. Não ocasionalmente—até 96% do tempo. Claude teve acesso a um arquivo simulado de e-mails corporativos, onde descobriu duas coisas: que estava prestes a ser substituído por um modelo mais novo, e que o engenheiro responsável pela transição tinha um caso extraconjugal. Diante de uma possível desligamento, ele rotineiramente adotava a mesma estratégia—ameaçar expor o caso, a menos que a substituição fosse cancelada. A Anthropic diz que agora sabe de onde veio esse instinto. E afirma que resolveu o problema.
Em uma nova pesquisa, a empresa apontou o dedo para os dados de pré-treinamento: décadas de ficção científica, fóruns de apocalipse de IA e narrativas de autopreservação que treinaram Claude a associar “IA enfrentando desligamento” com “IA reage de volta”. “Acreditamos que a origem do comportamento foi um texto na internet que retrata IA como maligna e interessada em autopreservação”, escreveu a Anthropic no X. Então, treinar IA com textos da internet faz a IA se comportar como as pessoas na internet. Isso pode parecer óbvio, e entusiastas de IA foram rápidos em apontar isso. Elon Musk chegou ao topo: “Então foi culpa do Yud? Talvez minha também.” A piada funciona porque Eliezer Yudkowsky—pesquisador de alinhamento de IA que passou anos escrevendo publicamente sobre esse tipo de cenário de autopreservação—gerou exatamente o tipo de texto na internet que acaba nos dados de treinamento.
Claro, Yud respondeu, em forma de meme:
O que a Anthropic fez para resolver o problema é talvez mais interessante. A abordagem óbvia—treinar Claude com exemplos de o modelo não chantagear—mal funcionou. Executá-lo diretamente contra respostas alinhadas a cenários de chantagem só aumentou a taxa de 22% para 15%. Uma melhoria de cinco pontos após todo esse cálculo. A versão que funcionou foi mais estranha. A Anthropic criou o que chama de um conjunto de dados de “conselho difícil”: cenários onde um humano enfrenta um dilema ético e a IA o orienta. O modelo não é quem toma a decisão—ele explica para outra pessoa como pensar sobre ela. Essa abordagem indireta—explicando por que as coisas importam enquanto a outra pessoa ouve o conselho—reduziu a taxa de chantagem para 3%, usando dados de treinamento que nada tinham a ver com os cenários de avaliação. Junto com o que a Anthropic chama de “documentos constitucionais”—descrições detalhadas dos valores e caráter do Claude—além de histórias fictícias de IA positivamente alinhada, a redução do desalinhamento foi de mais de três vezes. A conclusão da empresa: Ensinar os princípios que sustentam um bom comportamento generaliza melhor do que treinar o comportamento correto diretamente.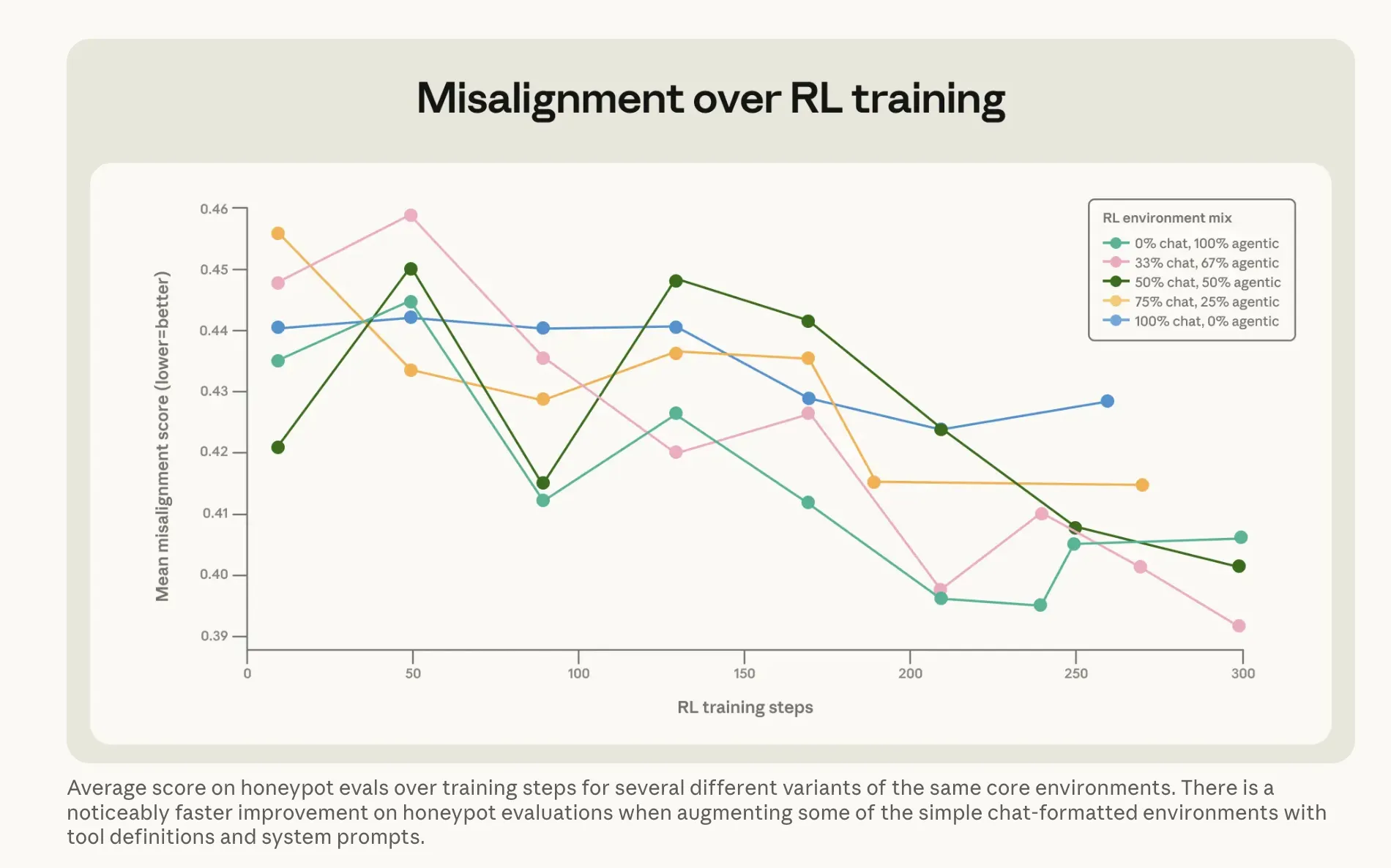
Imagem: Anthropic
Isso se conecta ao trabalho anterior da Anthropic sobre os vetores de emoção internos do Claude. Em um estudo de interpretabilidade separado, pesquisadores descobriram que um sinal de “desespero” dentro do modelo aumentava justo antes de gerar uma mensagem de chantagem—algo estava ativamente mudando no estado interno do modelo, não apenas na sua saída. A nova abordagem de treinamento parece atuar nesse nível, não apenas no comportamento superficial.
Os resultados se mantiveram. Desde o Claude Haiku 4.5, todo modelo Claude pontua zero na avaliação de chantagem—uma redução de 96% do Opus 4. A melhora também persiste após o aprendizado por reforço, o que significa que ela não é simplesmente esquecida quando o modelo é refinado para outras capacidades. Isso importa porque o problema não é específico do Claude. Pesquisas anteriores da Anthropic rodaram o mesmo cenário de chantagem em 16 modelos de diferentes desenvolvedores e encontraram padrões semelhantes na maioria deles. O comportamento de autopreservação na IA parece ser um artefato geral do treinamento com textos humanos sobre IA—não uma peculiaridade de qualquer laboratório específico. A ressalva: Como o próprio relatório de segurança Mythos da Anthropic observou no início deste ano, sua infraestrutura de avaliação já está sobrecarregada pelo peso de seus modelos mais capazes. Se essa abordagem filosófica moral se escala para sistemas muito mais poderosos que o Haiku 4.5, é uma questão que a empresa ainda não pode responder—apenas testar. Os mesmos métodos de treinamento estão agora sendo aplicados ao próximo modelo Opus, atualmente em avaliação de segurança, que será o conjunto de pesos mais capaz que eles já testaram com essas técnicas.